SQC
いまさら聞けない「機械学習」とは<2021年05月11日>

ーAI(人工知能)、機械学習、ディープラーニングの関係を
正しく理解し評価しようー
昨今、テレビやニュースで聞かない日はない「AI」について、皆さんはどれぐらい知っているでしょうか?まずAIとは何の略なのかご存知でしょうか?AIとは「Artificial Intelligence」の略で日本語にすると「人工知能」となります。
それでは人工知能とは一体何でしょうか。
人間のようにふるまう機械のことでしょうか?
一般社団法人人工知能学会では、人工知能の研究には二つの立場があると言っています。人間の知能そのものを持つ機械を作ろうとする立場と、人間が知能を使ってすることを機械にさせようとする立場の二つの立場です。そして実際の研究のほとんどは、人間が知能を使ってすることを機械にさせようとする立場にたっています。ですので、人工知能の研究と言っても、人間のような機械を作っているわけではありません。それでは実際の研究ではどのようなことをしているのか、いろいろな分野の研究で行われている「推論」と「学習」について簡単に説明しましょう。
「推論」とは知識をもとに新しい結論を得ることで、例えばオセロを自動で指す機械を考えます。機械には、以下の簡単なルール(知識)だけを教えておきます。
正しく理解し評価しようー
昨今、テレビやニュースで聞かない日はない「AI」について、皆さんはどれぐらい知っているでしょうか?まずAIとは何の略なのかご存知でしょうか?AIとは「Artificial Intelligence」の略で日本語にすると「人工知能」となります。
それでは人工知能とは一体何でしょうか。
人間のようにふるまう機械のことでしょうか?
一般社団法人人工知能学会では、人工知能の研究には二つの立場があると言っています。人間の知能そのものを持つ機械を作ろうとする立場と、人間が知能を使ってすることを機械にさせようとする立場の二つの立場です。そして実際の研究のほとんどは、人間が知能を使ってすることを機械にさせようとする立場にたっています。ですので、人工知能の研究と言っても、人間のような機械を作っているわけではありません。それでは実際の研究ではどのようなことをしているのか、いろいろな分野の研究で行われている「推論」と「学習」について簡単に説明しましょう。
「推論」とは知識をもとに新しい結論を得ることで、例えばオセロを自動で指す機械を考えます。機械には、以下の簡単なルール(知識)だけを教えておきます。
オセロ盤は8×8のマス目で自分と相手は交互に石を盤上に置く
石は片面黒と片面白で、先手が黒で後手が白
自分の石で相手の石を挟むと、相手の石を自分の石にできる
石を置くことができるのは、相手の石を挟むことのできる場所のみ
お互いに石を置くことができなくなれば終了
終了時に石の色の数が多いほうの勝ち
石は片面黒と片面白で、先手が黒で後手が白
自分の石で相手の石を挟むと、相手の石を自分の石にできる
石を置くことができるのは、相手の石を挟むことのできる場所のみ
お互いに石を置くことができなくなれば終了
終了時に石の色の数が多いほうの勝ち
このルールが知識にあたり、この知識を組み合わせて機械は勝ちを目指す中で、新しい結論を獲得します。それは「相手の石を多く挟めるが、相手に取られる石が少ない場所に置く」というものです。このように知識を組み合わせることで、目的を満たすために新しい結論を得ることが「推論」です。
次に「学習」について簡単に説明します。「学習」と聞くと何か機械が学習する感じがしますが、ここでは情報から将来使えそうな知識を見つけることです。例えば買い物内容の調査について考えます。コンビニのレジは以下の情報を得るとします。
一人目の客が「パン、おにぎり、牛乳」を購入
二人目の客が「牛乳、新聞」を購入
三人目の客が「お茶、お弁当」を購入
四人目の客が「パン、牛乳、ガム」を購入
二人目の客が「牛乳、新聞」を購入
三人目の客が「お茶、お弁当」を購入
四人目の客が「パン、牛乳、ガム」を購入
これらの情報から、パンを買った客は牛乳も一緒に買うことを学習します。ですので、パンと牛乳の売り場を近くにしておくともっと牛乳が売れるかもしれないと、考えることができます。このように客の買い物という情報から将来使えそうな知識を見つけ出す、これが人工知能の研究でいう「学習」です。
実際は「推論」と「学習」は単独で用いるよりも組み合わせて用いることが多いです。例えばカーナビは音声で操作でき、いろんな人が話した声を録音して集め情報とします。その声と内容の対応が将来使えそうな知識で、この知識をカーナビに予め入れておき、さらに新しい音声を取り込みます。学習した知識をもとに、推論の手法によって対応する命令の内容という新たな結果を導き出します。このように「推論」と「学習」は組み合わされて人工知能の研究は行われています。
人工知能の研究には、多くの場合情報が必要不可欠です。情報とは先の例でいうと、オセロの場合盤面のどこに何色の石が置かれているのかに当たり、コンビニのレジの場合客の購入履歴になります。このように推論や学習を行うためには、多くの情報(データ)が必要になります。近年、計算機ハードの性能の飛躍的な向上やクラウドの利用に伴って「ビッグデータ」と呼ばれる多次元(説明変数の数が多いこと)でかつ大標本(サンプル数が多いこと)なデータが容易に取得できるようになりました。またこのビッグデータを処理できる計算機も比較的安価で購入でき、ますます人工知能の研究が盛んになってきています。
人工知能の技術の根幹をなすのは、ディープラーニングをはじめとした機械学習です。機械学習とは、観測センサーやその他様々な手段で収集されたデータの中から一貫性のある規則を見つけ出そうとする研究で、数学の統計の分野と強い関連があり、人工知能研究の殆どの分野で利用されています。ではそもそもの人工知能とは一体いつから言われているのでしょうか。最近の人工知能ブームは、第三次人工知能ブームと言われています。人工知能という言葉が生まれたのは1956年のダートマス会議で初めてその言葉が使われました。第一次人工知能ブームは1960年代でパーセプトロンやニューラルネットワークなどの数多くのアルゴリズムや技術がこの時に開発されました。しかしこの時の人工知能では、現実にある複雑な問題は解けないということでブームは去りました。第二次人工知能ブームは知識表現が発展したエキスパートシステムによるもので1980年代に盛んになりました。このときのブームの先駆けはなんと日本でした。日本の第5世代コンピュータプロジェクトが火付け役となりブームは起こりました。しかしこのエキスパートシステムでは、人間すべての知識を機械に記入することはできないという根本的な問題にぶち当たり第二次人工知能ブームは終わりを迎えます。そして現在の第三次人工知能ブームはディープラーニング(深層学習)の登場とGPU(Graphics Processing Unit)性能の飛躍的向上によって発生します。深層学習とは、ごく簡単に説明すると第一次人工知能ブームで考案されたパーセプトロンとニューラルネットワーク、第二次人工知能ブームでの誤差逆伝搬法を用いて多層に結合することで、データを基に機械が自ら特徴量を学習する特徴表現学習が可能になり、これまでの技術よりも性能が飛躍的に向上し実用が加速しています。
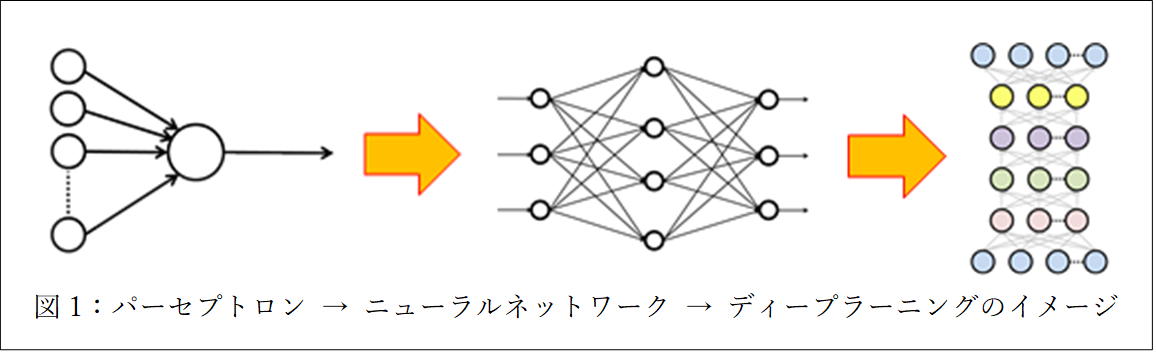
このディープラーニングの技術を様々な分野に応用することで、いろいろなサービスが行われています。例えば、ゲームの分野では囲碁のAlpha Go。質問応答システムのWatson、画像を生成するサービスOOH AI、またAIスピーカーであるGoogle HomeやAmazon Alexa、Googleが行っているコロナ感染者数予測など枚挙に暇がない。しかしこれらのサービスでは、ある特徴がある。それは人工知能による結果が80%程度当たってさえいればよく、しかもそれがなぜ当たっているのか分からなくても良い場面が多いということです。
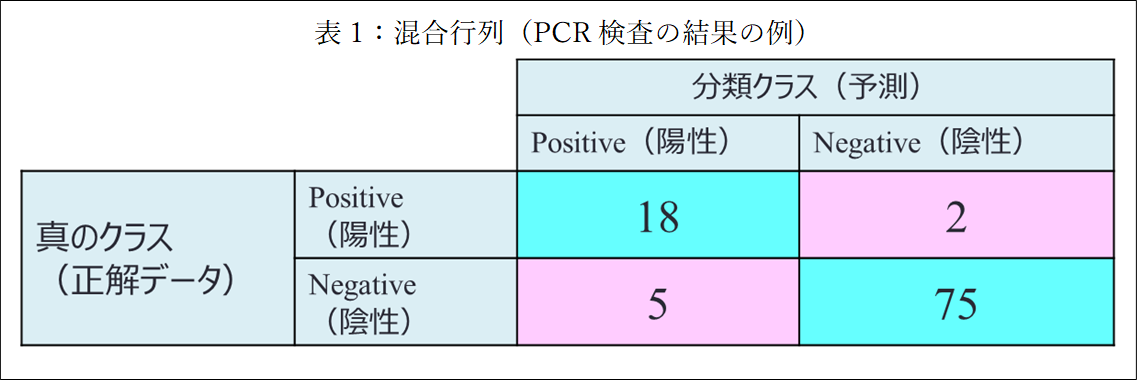
しかし実際に機械学習を業務で使用する場合、なぜ当たっているのかわからないと困る場面も多いです。そのためには機械学習で何をやっており、それがどのように評価されているのかをしっかり理解する必要があります。特に評価について理解することは、実際にその技術を使用した場合に正しく把握するために必要になります。例えば、コロナ感染の有無を調べるPCR検査の評価について考えてみましょう。予測の正解率は80%とされている場合、それは何を意味するのでしょうか。100人の感染者の検査の結果80人の感染を当てることができれば80%の正解率ということになります。一方で、100人の非感染者のうち80人は非感染者であると当てることも80%の正解率ということになります。どちらも80%の正解率には違いありませんが、大きく異なります。ですので、この分野の研究者は正答率だけでは正しく評価できないと言うでしょう。テレビでも聞くようになった偽陽性や偽陰性はこの正答率と対をなす評価方法です。それらについて表を用いて簡単に説明します。
20人の新型コロナウィルス陽性者と80人の陰性者を合わせた100人のPCR検査を行ったとします。検査の結果、23人が陽性と77人が陰性と予測されました。それをまとめたのが表1です。この表は混合行列と呼ばれ、縦方向が正解を横方向が予測を表しています。真のクラスが陽性で分類クラスも陽性が18人、真のクラスが陽性で分類クラスの陰性が2人、真のクラスが陰性で分類クラスの陽性が5人、真のクラスも分類クラスも陰性なのが75人であると読み取ります。この時、いわゆる正解率というのは(18+75)/(18+5+75+2)=93%となります。機械学習の研究では他に適合率と再現率と呼ばれる評価指標を用いるのが一般的です。適合率とはこの場合、陽性者と判断した内、本当に陽性者だった割合を指します。ですので、式は18/(18+5)=78%となります。つまり本当は陰性なのに陽性と判定してしまう偽陽性があるということです。一方で再現率とはこの場合、本当の陽性者の内、何人を陽性ということができた割合を指します。ですので、式は18/(18+2)=90%となります。つまり本当は陽性なのに陰性と判定してしまう偽陰性があるということになります。このように正しい評価方法、言葉の正しい意味を知っているかどうかはとても大切です。
機械学習には正解データが与えられる教師あり学習と、正解データがない教師なし学習の二つがあります。
教師あり学習にも目的変数が質的変数である分類と目的変数が量的変数である回帰の問題に大別されます。分類とは例えば、大量のメールから迷惑メールなのか迷惑メールではないかを過去のデータから学習し、新たなメールを受信した時にそのメールが迷惑メールなのか迷惑メールでないかの分類を行います。この分類手法には様々な手法があります。例えば、本セミナーでも扱う判別分析やサポートベクターマシン(SVM)、決定木やランダムフォレストなどが挙げられます。判別分析とは各クラスが多変量正規分布していると仮定し、各クラス内の分散が小さく、各クラス間の距離が大きくなる直線上へ写像し分類する方法です。サポートベクターマシン(SVM)とはマージン最大化を行うことで判別超平面を作成し分類する方法です。決定木とは評価関数が小さくなるように段階的にデータを分割していき、木構造のモデルを作成し分類する方法です。またランダムフォレストとは、その決定木をバギングと呼ばれるアンサンブル学習を用いて構築したもので、簡単に説明すると複数の決定木を構築しその多数決によってデータを分類する方法です。それぞれの手法には表2に示すような特徴が挙げられ、またそれぞれの手法にもメリット・デメリットが存在します。本セミナーでは機械学習手法を用いる上で必要な知識及び、機械学習手法の原理とそのメリット・デメリット、機械学習手法の評価方法などを正しく理解し、用いることができる一助となるようなものを目指しています。

西垣 貴央(にしがき たかひろ)
青山学院大学 理工学部経営システム工学科 助教
2011年 京都工芸繊維大学 工芸科学部 情報工学課程 卒業
2017年 東京工業大学大学院 総合理工学研究科 知能システム科学専攻 博士課程修了
専門分野は独立成分分析、テキストマイニング、統計的機械学習。
独立成分分析をテキスト分析に適応した独立話題分析に関する研究の他、機械学習を利用した異常検知技術や画像認識などの研究にも従事。
日科技連主催「モノづくりにおける問題解決のためのデータサイエンス入門コース」講師






〈お問い合わせ先〉一般財団法人 日本科学技術連盟 品質経営研修センター 研修運営グループ
〒166-0003 東京都杉並区高円寺南1-2-1 / TEL:03-5378-1213
Copyright © 2021 Union of Japanese Scientists and Engineers. All rights Reserved.